How to write SageMaker code faster with AWS CodeWisperer
Staying current in the tech world means being familiar with AI-powered coding tools. You've likely encountered GitHub Copilot and an alternative developed by Amazon, CodeWhisperer.
CodeWhisperer is a general-purpose, machine learning powered code generator that provides real-time code recommendations. As you write code, CodeWhisperer automatically generates suggestions based on your existing code and comments.
Why choose CodeWhisperer (now part of Amazon Q Developer) over Copilot? The key advantage is CodeWhisperer's specialization in the Amazon Web Services environment. It provides targeted guidance and suggestions for AWS-related coding and infrastructure, making it a particularly valuable tool for developers working within the AWS ecosystem.
Installation
If you are using SageMaker Studio/Canvas, the CodeWisperer is preinstalled (amazon-q-developer-jupyterlab-ext), and you can skip this section.
If you are running Jupiter locally or outside of SageMaker Studio, please run the commands below to get it installed.
Jupyter Lab version >= 4.0
pip install amazon-codewhisperer-jupyterlab-ext
sudo systemctl restart jupyter-serverJupyter Lab version >= 3.6 and < 4.0
pip install amazon-codewhisperer-jupyterlab-ext~=1.0
jupyter server extension enable amazon_codewhisperer_jupyterlab_ext
sudo systemctl restart jupyter-serverWorking with CodeWisperer
In the Jupyter, start writing the code description as a comment and then press Alt+C (Windows) or Option+C (MacOs).
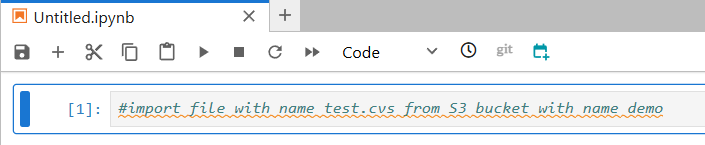
You will see a few options offered. Use the Up/Down button to select the optimal one and then press the Tab button to accept the result.
#import file with name test.cvs from S3 bucket with name demo
s3.download_file('demo-bucket-1', 'test.csv', 'test.csv')Easy. Right?
Below are a few examples generated by CodeWisperer.
#using Pandas read CSV file test.csv from S3 bucket demo
df = pd.read_csv('s3://demo-bucket-1/test.csv')
df.head()#split dataset into training and validation with 0.1 ratio
train, val = train_test_split(df, test_size=0.1, random_state=42)#save training and validation data to csv
train.to_csv('train.csv', index=False)
val.to_csv('val.csv', index=False)# create a sagemaker job which does liner regression on test.cvs file stored at s3 demo
# use container with xgboost model
container = sagemaker.image_uris.retrieve(region=boto3.Session().region_name, framework='xgboost', version='latest')
print(container)# use container with xgboost model
container = sagemaker.image_uris.retrieve(region=boto3.Session().region_name, framework='xgboost', version='latest')# configure training job
xgb = sagemaker.estimator.Estimator(image_uri=container,
role=role,
instance_count=1,
instance_type='ml.m4.xlarge',
output_path=output_location,
sagemaker_session=sagemaker_session)# set hyperparameters
xgb.set_hyperparameters(max_depth=5,
eta=0.2,
gamma=4,
min_child_weight=6,
subsample=0.8,
silent=0,
objective='binary:logistic',
num_round=100)As you can see, CodeWisperer helps you generate boilerplate code and save time searching for a function to call, but it is still your responsibility to update the code with the required parameters. Of course, developing code will still be challenging without knowing what you are doing, so it is highly recommended that you learn the theory first.
In conclusion, I'd like to recommend a few links that may help you master SageMaker.
1) https://www.kaggle.com/ - Tons of free datasets for experiments and free courses about ML. At the time of writing, it had 413k datasets, 1.2m notebooks, and 13400 models.
2) https://sagemaker.readthedocs.io/ - Amazon SageMaker Python SDK documentation.
3) https://docs.aws.amazon.com/sagemaker/latest/dg/algos.html - List of built-in algorithms and pretrained models in Amazon SageMaker.
4) https://docs.aws.amazon.com/sagemaker/latest/dg-ecr-paths/sagemaker-algo-docker-registry-paths.html - List of Docker images with SageMaker models and example code.
Looking for help? Reach me anytime.